
3 Ways You will Get More Deepseek Ai While Spending Less
페이지 정보
작성자 Tracey 작성일25-02-23 11:30 조회3회 댓글0건본문
 Free DeepSeek v3’s specialized modules, similar to DeepSeek Math and DeepSeek VL, give it a major edge in dealing with tasks that require area-particular data. Microsoft is interested in offering inference to its customers, but much much less enthused about funding $one hundred billion data centers to practice main edge fashions which might be more likely to be commoditized lengthy before that $100 billion is depreciated. DeepSeek is a way more affordable possibility with base charges approx 27.Four occasions cheaper per token than OpenAI’s o1. Given that Singapore itself isn't involved a lot in the AI race, this has raised the prospects of a loophole considerably. Figure 3: Blue is the prefix given to the mannequin, green is the unknown textual content the model ought to write, and orange is the suffix given to the model. DeepSeek reportedly educated its base model - referred to as V3 - on a $5.Fifty eight million funds over two months, based on Nvidia engineer Jim Fan. In its Korean-language response, high right, the chatbot referred to as kimchi ″a dish that represents Korean tradition and history.″ However, the chatbot mentioned the dish was solely ″related to Korea″ in its response to English users, middle proper.
Free DeepSeek v3’s specialized modules, similar to DeepSeek Math and DeepSeek VL, give it a major edge in dealing with tasks that require area-particular data. Microsoft is interested in offering inference to its customers, but much much less enthused about funding $one hundred billion data centers to practice main edge fashions which might be more likely to be commoditized lengthy before that $100 billion is depreciated. DeepSeek is a way more affordable possibility with base charges approx 27.Four occasions cheaper per token than OpenAI’s o1. Given that Singapore itself isn't involved a lot in the AI race, this has raised the prospects of a loophole considerably. Figure 3: Blue is the prefix given to the mannequin, green is the unknown textual content the model ought to write, and orange is the suffix given to the model. DeepSeek reportedly educated its base model - referred to as V3 - on a $5.Fifty eight million funds over two months, based on Nvidia engineer Jim Fan. In its Korean-language response, high right, the chatbot referred to as kimchi ″a dish that represents Korean tradition and history.″ However, the chatbot mentioned the dish was solely ″related to Korea″ in its response to English users, middle proper.
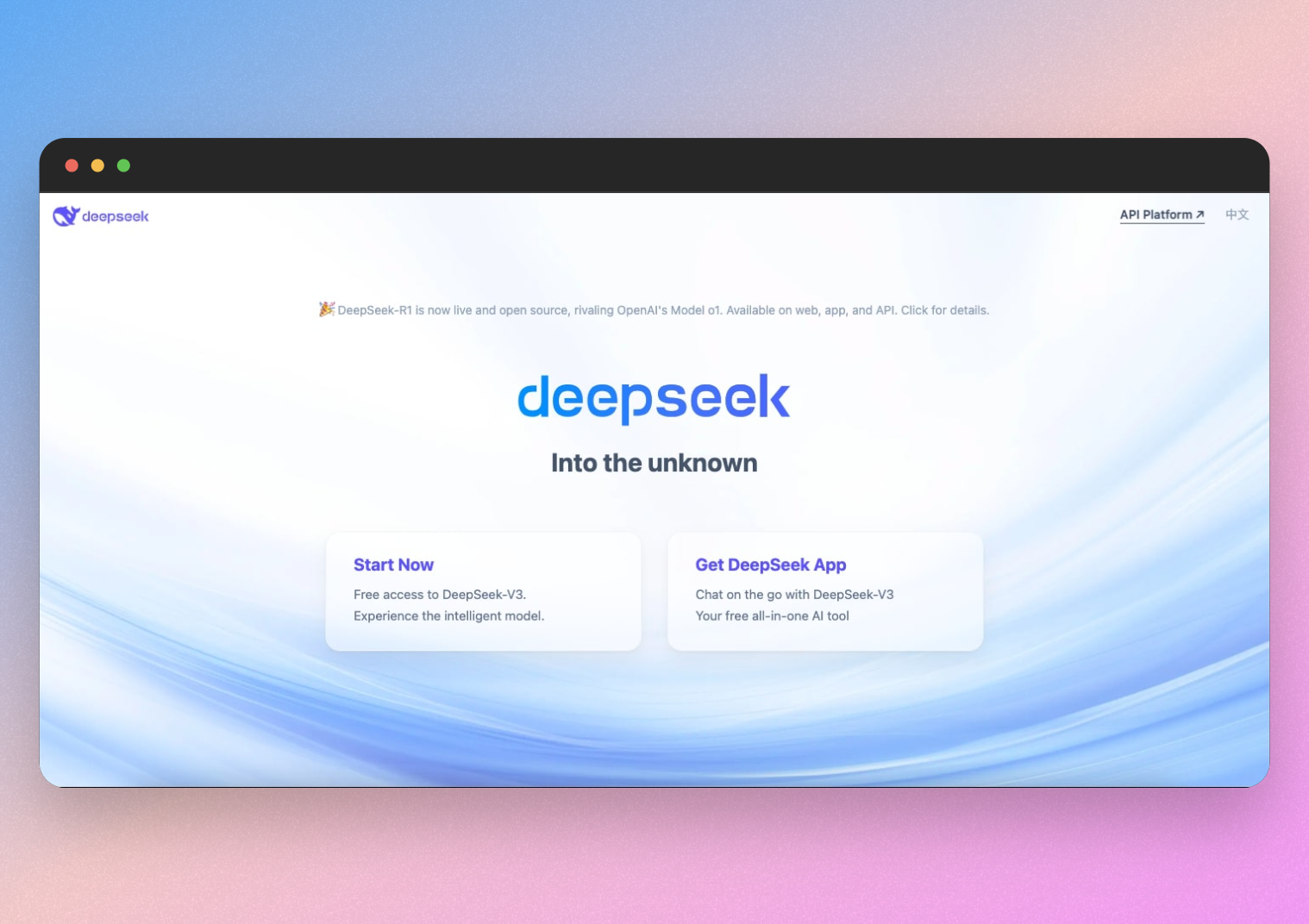
Depending on the language of the inquirer, the DeepSeek AI chatbot delivered different responses to a query about kimchi's origin. In its Chinese-language response, backside right, DeepSeek mentioned kimchi was Chinese, not Korean, in origin. Comparison between DeepSeek and ChatGPT exhibits competitive capabilities. However, with future iterations specializing in refining these capabilities utilizing CoT techniques, enhancements are on the horizon. Concerns over whether it will have an effect on future investments in AI technology. Beijing's regulatory atmosphere and national safety priorities further complicate DeepSeek's future. This strategy differs significantly from DeepSeek's R-1 and R-1-Zero models. While R-1 makes use of a simpler reinforcement learning process with rule-based mostly feedback, R-1-Zero took an much more minimal method, coaching solely with reinforcement learning and no extra knowledge. Uses vector embeddings to retailer search data efficiently. Their research also confirmed that efficient reasoning fashions do not need sophisticated components like Monte-Carlo Tree Search - similar to what DeepSeek-R1's builders found. The paper goes on to discuss how despite the RL creating unexpected and powerful reasoning behaviors, this intermediate mannequin, DeepSeek-R1-Zero, did face some challenges, together with poor readability, and language mixing (starting in Chinese and switching over to English, for example).
Instead of utilizing worth capabilities to guage intermediate steps, the workforce targeted on the final final result. Nvidia’s shares dropped by about 17%, wiping nearly $600 billion off its market value. By August, that value grew to $3.3 billion after additional investment from Tencent and Gaorong Capital. For these unaware, DeepSeek is alleged to have computational sources value over $1.6 billion and has round 10,000 of NVIDIA's "China-particular" H800 AI GPUs and 10,000 of the higher-end H100 AI chips. Mr. Estevez: Second, you already know, we do have some authorized parameters below which we will high quality, and you know what the caps are round that. DeepSeek’s MoE architecture operates equally, activating solely the mandatory parameters for every activity, resulting in significant cost savings and improved performance. The team additionally discovered that increasing the context length (as much as 128k tokens) persistently improved performance by allowing for more complex reasoning. Additionally they created extra training data showing detailed step-by-step reasoning. For tasks with clear right or mistaken solutions, like math problems, they used "rejection sampling" - generating multiple answers and keeping only the correct ones for training.
Traditional AI is used greatest for performing particular tasks that have been programmed. Moonshot AI's new multimodal Kimi k1.5 is displaying impressive results in opposition to established AI fashions in complicated reasoning duties. Since detailed reasoning (long-CoT) produces good outcomes however requires extra computing power, the workforce developed ways to switch this knowledge to fashions that give shorter solutions. Their success in transferring knowledge from longer to shorter models mirrors a broader industry development. Anthropic in all probability used related data distillation methods for its smaller but highly effective latest Claude 3.5 Sonnet. In January, the Artificial Intelligence firm headed by quantum trader Liang Wenfeng put out its latest mannequin. The Republican Senator from Missouri Josh Hawley has introduced a brand new bill that may make it illegal to import or export synthetic intelligence merchandise to and from China, that means somebody who knowingly downloads a Chinese developed AI mannequin like the now immensely well-liked DeepSeek may face as much as 20 years in jail, a million dollar superb, or both, should such a law pass. Human intelligence is a complex phenomena that arises not from realizing quite a lot of issues but slightly our capacity to filter out things we don’t need to know with a view to make decisions.
댓글목록
등록된 댓글이 없습니다.