
Thirteen Hidden Open-Source Libraries to Grow to be an AI Wizard
페이지 정보
작성자 Fred 작성일25-03-10 02:43 조회2회 댓글0건본문
 Listed here are the fundamental necessities for running DeepSeek locally on a computer or a mobile gadget. Download the mannequin that fits your system. This statement leads us to believe that the means of first crafting detailed code descriptions assists the model in additional successfully understanding and addressing the intricacies of logic and dependencies in coding tasks, notably these of upper complexity. Aider permits you to pair program with LLMs to edit code in your native git repository Start a new project or work with an current git repo. The key innovation on this work is the use of a novel optimization method referred to as Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. Amongst all of those, I think the attention variant is almost certainly to vary. 2x speed improvement over a vanilla consideration baseline. Model quantization allows one to cut back the reminiscence footprint, and improve inference velocity - with a tradeoff in opposition to the accuracy. AMD GPU: Enables working the DeepSeek-V3 model on AMD GPUs via SGLang in each BF16 and FP8 modes. LMDeploy: Enables environment friendly FP8 and BF16 inference for local and cloud deployment. Therefore, if you are dissatisfied with Free DeepSeek Chat’s information management, native deployment on your computer would be an excellent different.
Listed here are the fundamental necessities for running DeepSeek locally on a computer or a mobile gadget. Download the mannequin that fits your system. This statement leads us to believe that the means of first crafting detailed code descriptions assists the model in additional successfully understanding and addressing the intricacies of logic and dependencies in coding tasks, notably these of upper complexity. Aider permits you to pair program with LLMs to edit code in your native git repository Start a new project or work with an current git repo. The key innovation on this work is the use of a novel optimization method referred to as Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. Amongst all of those, I think the attention variant is almost certainly to vary. 2x speed improvement over a vanilla consideration baseline. Model quantization allows one to cut back the reminiscence footprint, and improve inference velocity - with a tradeoff in opposition to the accuracy. AMD GPU: Enables working the DeepSeek-V3 model on AMD GPUs via SGLang in each BF16 and FP8 modes. LMDeploy: Enables environment friendly FP8 and BF16 inference for local and cloud deployment. Therefore, if you are dissatisfied with Free DeepSeek Chat’s information management, native deployment on your computer would be an excellent different.
That is sensible because the mannequin has seen appropriate grammar so many occasions in training information. Starting from the SFT mannequin with the final unembedding layer eliminated, we educated a mannequin to take in a prompt and response, and output a scalar reward The underlying goal is to get a model or system that takes in a sequence of text, and returns a scalar reward which should numerically signify the human desire. In the future, we intention to use our proposed discovery course of to provide self-enhancing AI analysis in a closed-loop system utilizing open models. Here’s how to make use of it. Specifically, we use reinforcement studying from human suggestions (RLHF; Christiano et al., 2017; Stiennon et al., 2020) to fine-tune GPT-three to follow a broad class of written instructions. The internal memo stated that the company is making enhancements to its GPTs based mostly on customer feedback. Although DeepSeek released the weights, the training code just isn't obtainable and the company did not launch much data about the training information. This information is of a distinct distribution. The quantity of capex dollars, gigawatts of electricity used, sq. footage of latest-construct information centers, and, of course, the variety of GPUs, has completely exploded and seems to point out no sign of slowing down.
Pre-training: The model learns next token prediction utilizing large-scale web data. Model Quantization: How we are able to significantly improve mannequin inference prices, by improving memory footprint by way of using less precision weights. The rule-primarily based reward mannequin was manually programmed. Each model within the series has been skilled from scratch on 2 trillion tokens sourced from 87 programming languages, ensuring a comprehensive understanding of coding languages and syntax. AMC Athena is a comprehensive ERP software program designed to streamline enterprise operations across numerous industries. It’s sharing queries and information that might embrace extremely private and delicate business info," stated Tsarynny, of Feroot. How nicely does DeepSeek carry out on mathematical queries? There are others as nicely. The US may still go on to command the sector, however there is a way that DeepSeek has shaken a few of that swagger. So all those companies that spent billions of dollars on CapEx and buying GPUs are nonetheless going to get good returns on their investment. It should get too much of consumers. Will future versions of The AI Scientist be able to proposing concepts as impactful as Diffusion Modeling, or provide you with the subsequent Transformer architecture? The introduction of The AI Scientist marks a big step in the direction of realizing the total potential of AI in scientific analysis.
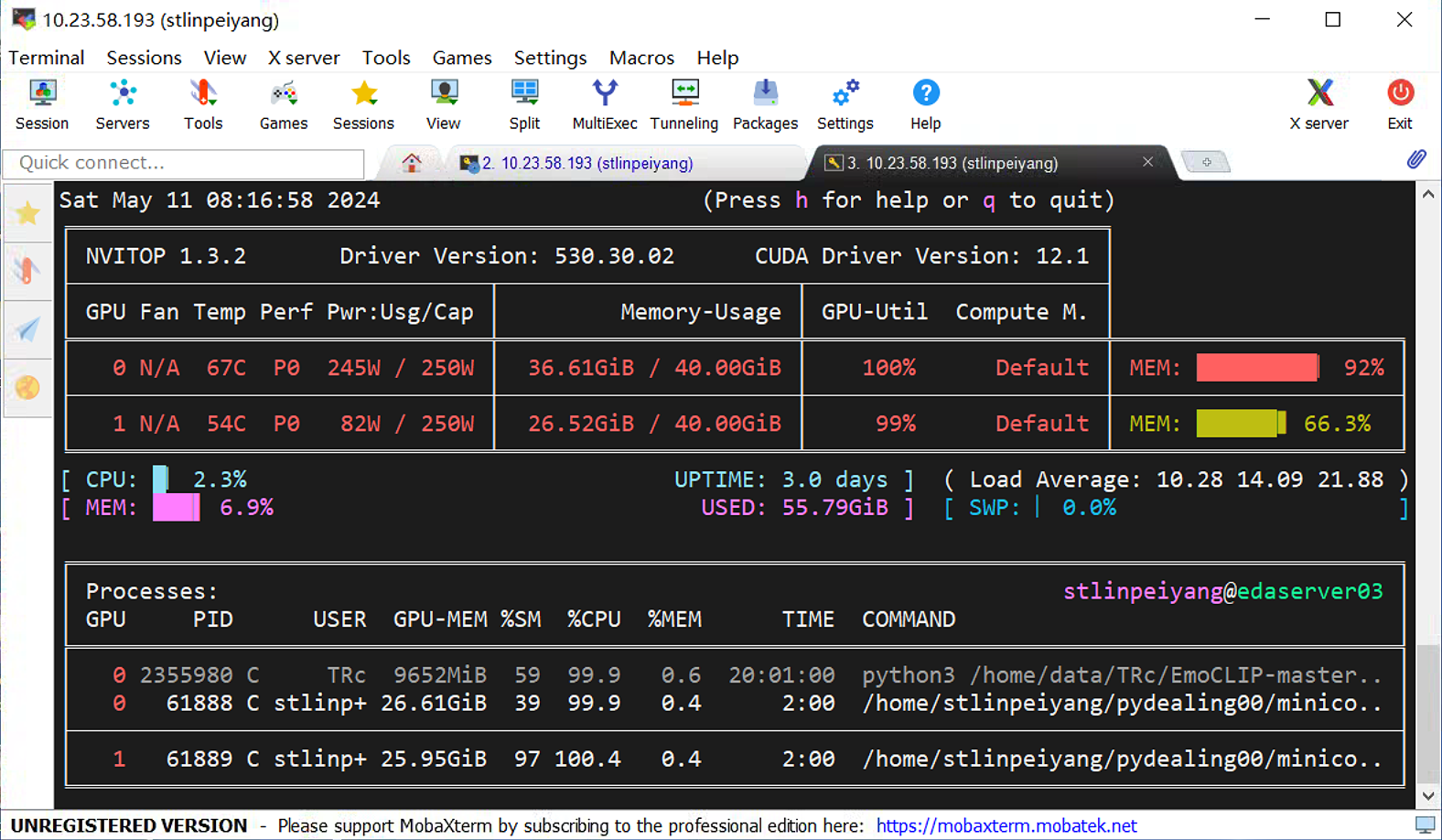 This analysis represents a big step ahead in the sector of large language fashions for mathematical reasoning, and it has the potential to affect numerous domains that rely on superior mathematical expertise, comparable to scientific research, engineering, and training. Some fashions are educated on bigger contexts, however their effective context length is normally a lot smaller. But it isn't far behind and is way cheaper (27x on the DeepSeek cloud and round 7x on U.S. DeepSeek-R1 is just not only remarkably efficient, however it's also far more compact and fewer computationally expensive than competing AI software, resembling the latest version ("o1-1217") of OpenAI’s chatbot. Storage: Minimum 10GB of Free DeepSeek r1 space (50GB or more recommended for larger fashions). Processor: Multi-core CPU (Apple Silicon M1/M2 or Intel Core i5/i7/i9 really helpful). RAM: At least 8GB (16GB advisable for bigger models). Then again, OpenAI has not made its AI models out there in China. We first hire a group of 40 contractors to label our information, based mostly on their performance on a screening tes We then acquire a dataset of human-written demonstrations of the desired output conduct on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to practice our supervised studying baselines.
This analysis represents a big step ahead in the sector of large language fashions for mathematical reasoning, and it has the potential to affect numerous domains that rely on superior mathematical expertise, comparable to scientific research, engineering, and training. Some fashions are educated on bigger contexts, however their effective context length is normally a lot smaller. But it isn't far behind and is way cheaper (27x on the DeepSeek cloud and round 7x on U.S. DeepSeek-R1 is just not only remarkably efficient, however it's also far more compact and fewer computationally expensive than competing AI software, resembling the latest version ("o1-1217") of OpenAI’s chatbot. Storage: Minimum 10GB of Free DeepSeek r1 space (50GB or more recommended for larger fashions). Processor: Multi-core CPU (Apple Silicon M1/M2 or Intel Core i5/i7/i9 really helpful). RAM: At least 8GB (16GB advisable for bigger models). Then again, OpenAI has not made its AI models out there in China. We first hire a group of 40 contractors to label our information, based mostly on their performance on a screening tes We then acquire a dataset of human-written demonstrations of the desired output conduct on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to practice our supervised studying baselines.
Here's more info about DeepSeek r1 (socialbookmarkssite.com) check out our own webpage.
댓글목록
등록된 댓글이 없습니다.